Everything you need to evaluate open-source (vs. closed-source) LLMs

Businesses are under growing pressure to integrate artificial intelligence into their products. But should you go for an open-source or closed-source large language model (LLM)?
Large language models (LLMs) are a class of machine learning models that can process and generate human-like natural language. Their main purpose is to generate coherent and contextually relevant text, following a (hopefully well-crafted!) prompt.
This article is a guide to understanding the pros and cons of open- and closed-source approaches. You’ll learn the differences between them, and get a sense of their availability, cost, intellectual property rights status, security measures, and more. I’ll also provide an overview of the current state of both fields, ethical considerations, and notable open-source LLMs.
This is a rapidly evolving space, especially when it comes to licensing agreements and technical compatibility. Consult with technical and legal experts before implementing your chosen solution.
Basic definitions
Open-source LLMs possess publicly available source code, model architecture, and pre-trained weights. This makes them more transparent. Researchers can access their underlying models, inspect training data, and customise the code. They promote reproducibility and likely adhere to ethical research standards, at least in the development and training phases, because they expect to be publicly scrutinised.
Closed-source LLMs have proprietary source code and model weights, which are not publicly accessible. This restricts customisation and adaptation possibilities. They are proprietary, run by companies that do not disclose their models, training data, or code, making independent inspection, verification, and reproducibility difficult.
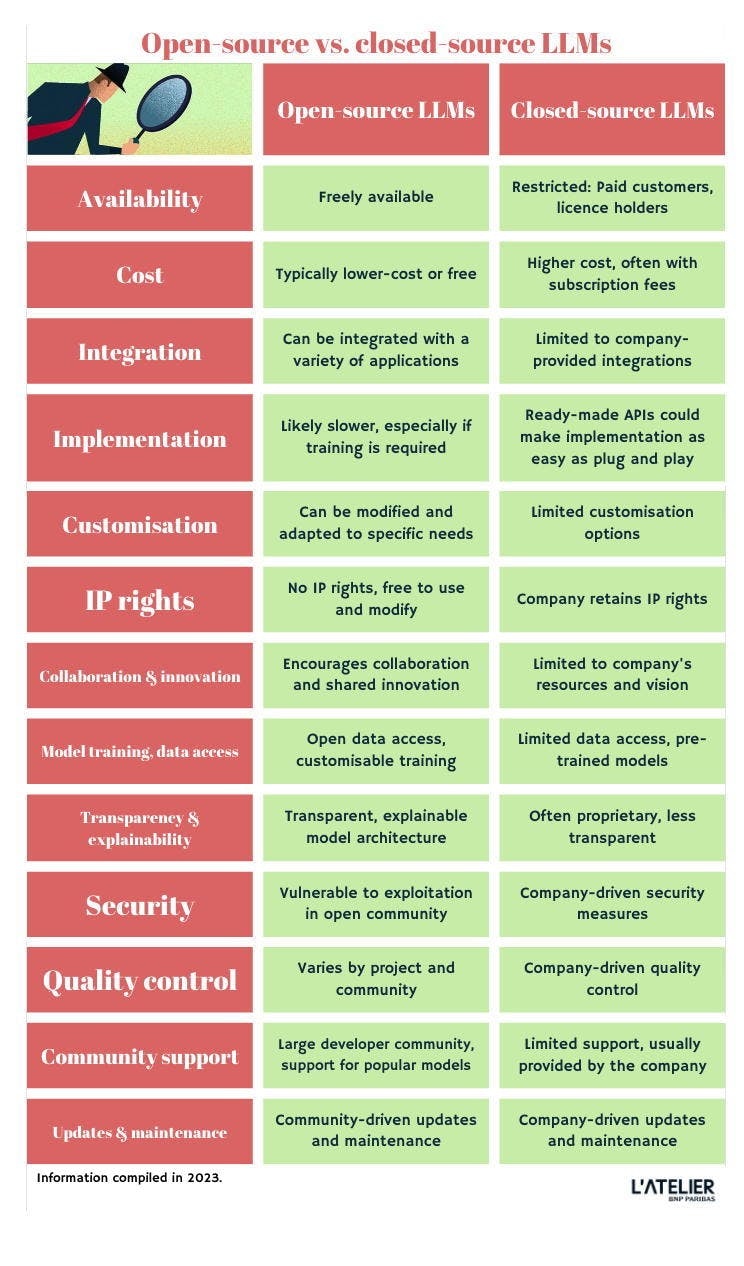
Comparing LLMs: what to keep track of
The table above highlights key differences between open-source and closed-source. There are edge-cases that challenge the open- versus closed- classification, so consider this a starting point for your own research. The choice between open or closed ultimately depends on factors like budget, your bespoke requirements, and desired level of customisation and integration.
There is no one-size-fits-all. Open-source is a clear frontrunner when it comes to cost and adaptability, but closed-sourced solutions can be better-performing and more secure.
The current state of the sector
Organisations like Databricks, Stanford, and German nonprofit LAION are working to democratise access to LLMs (as opposed to proprietary models like ChatGPT), currying debate around whether AI models should be freely available or protected by copyright, and raising the ethical and security implications of using open-source LLMs.
The open-source debate intensified with the release of GPT-4, which came with a technical report but no details about the model's architecture, hardware, or training method. Critics argue that this makes it appear open-source and academic, even though it is. OpenAI, once a supporter of open-source, cited safety concerns as a reason for keeping models closed.
It merits mention that open-source AI played a significant role in AI advancement, with most popular LLMs having been built on open-source architectures like Transformers. The shift by companies toward proprietary commercial models has also raised concerns about transparency and accessibility, boosting the popularity of open-source overall.
But different levels of openness are more likely to strike the necessary balance; the future ecosystem will likely have a diverse range of options. The research that open-source models permit is essential. And while adequate for many applications, small open-source LLMs, such as Vicuna, may not be as cutting-edge as ChatGPT and other proprietary solutions.
What are the ethical considerations?
Contrary to popular belief, Both open-source and closed-source LLMs have ethical implications; only some are mitigated by choosing an open-source solution. Here are some of the ethical risks, and the likely best option for addressing them:
- Potential biases in training data: LLMs are trained on vast amounts of text data, which may contain biases present in the source material. These can be unintentionally perpetuated by the model; take a look at our piece on this topic specifically to understand what implications this can have. Open-source LLMs are more likely to have their training data and methods scrutinised by the research community, which can help identify biases. Closed-source LLMs may have less transparency in this regard.
- Privacy concerns: LLMs may inadvertently generate text that discloses sensitive information, especially if their training data contains private or personally identifiable information (PII). Open-source LLMs provide more transparency about data sources and methods, allowing developers to make informed decisions about privacy risks. But the open nature of their models also make it easier for malicious actors to exploit weaknesses.
- “Hallucinations”: LLMs may generate false or misleading information, with severe consequences for information accuracy and trustworthiness. Open-source LLMs allow users to verify that AI systems are trained on accurate and contextually relevant datasets. This can reduce—but won’t entirely eliminate—the incidence of hallucinations. Nobody really knows why they occur.
- Responsible use of AI-generated content: AI-generated content can be used for various purposes, including misinformation and deepfake creation. Open-source LLMs make it easier for malicious actors to access and misuse powerful AI tools. Closed-source LLMs provide more control over use, at the cost of reduced accessibility for researchers and developers.
Without further ado: Your shortlist of open-source LLMs
The table below includes only state-of-the-art chatbot-related releases with permissive licensing. Note that “open source” can mean many things, and the legal frameworks of the options you're considering should be verified before investing too much into implementation, especially for commercial use.
The LLMs closest to open source that have been released are licenced under Apache 2.0; which is considered a permissive licence. Learn more about Apache’s 2.0 licence in lay terms.
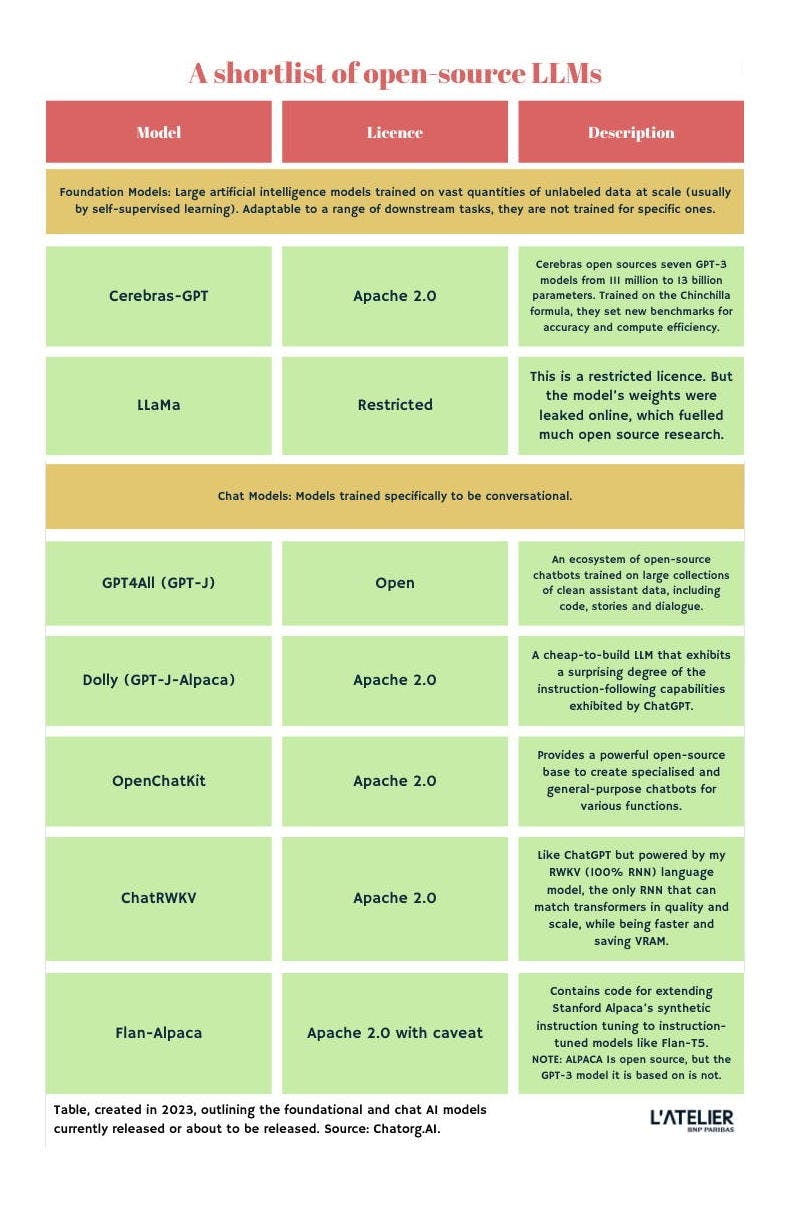
L'Atelier's open-source LLM shortlist
The big takeaways
- Open-source LLMs offer several advantages for the development of our technology tools—such as increased transparency, accessibility, and ability to target data they have analysed. They allow us to innovate by allowing developers to modify, personalise, and distribute models with fewer restrictions.
- Open-source AI models have demonstrated impressive performance, and can be optimised to run on low-powered devices. Their limitations, however, include legal concerns related to data privacy, the security of the dataset and its licensing, and misuse of the user-facing interface.
- Closed-source LLMs provide more control over data privacy and security. Though less flexible, proprietary models, like OpenAI's GPT-4, are typically backed by extensive research and development investments, leading to state-of-the-art performance. By opting for closed-source LLMs, businesses can benefit from the latest advancements in AI while maintaining control over data and mitigating the risks and costs of running and maintaining a proprietary AI model.
The prevalence of proprietary large language models (LLMs) has sparked a default movement toward open-source AI models. While state-of-the-art LLMs require significant resources and expertise to develop, open-source AI aims to democratise access to these tools. Recent examples include Dolly, which demonstrated impressive performance despite having fewer parameters, and lower computing requirements than proprietary counterparts.
But the debate surrounding accessibility and ownership of AI models is just beginning. Open-source advocates argue that AI models should be freely available for modification and distribution, while others call for copyright protection and licencing. As the landscape evolves, it's crucial for organisations to carefully consider the ethical, security, and transparency implications of AI models for themselves.
07 Dec 2023
-
Giorgio Tarraf
Illustration by Thomas Travert.
Want a weekly digest?
02/03
Related Insights

AI’s biggest leap is hiding in plain sight … and it’s not LLMs
AI-powered visual analysis spots complex medical conditions and guides 30-tonne trucks on public roads, making it among the most transformative technologies today—even if it doesn’t make headlines like large language models.

Digital Adoption is Transforming Dissent... and Facilitating the Rise of the State
It is tempting to reduce dissent to a series of disruptive activities. But it’s crucial to remember it is a direct response to the acts of public institutions and structures of authority. In the virtual world, however, the state feels less visible. This is about to change.

How universal basic income could fuse public goods to virtual economy interests
Covid-19 has normalised unconditional welfare transfers, even in societies traditionally resistant to public “giveaways.” What existing precedent exists for universal basic income, and how could it impact the virtual economy ... not to mention the one most of us still live in?
03/03
L’Atelier is a data intelligence company based in Paris.
We use advanced machine learning and generative AI to identify emerging technologies and analyse their impact on countries, companies, and capital.